Scaling AI Performance: Meta's KernelEvolve Automates Kernel Optimization Across Heterogeneous Hardware
Introduction
Meta's AI infrastructure powers billions of daily interactions, from personalized recommendations to generative AI assistants. Underneath these services lies a complex hardware ecosystem comprising NVIDIA GPUs, AMD GPUs, Meta's custom MTIA silicon chips, and CPUs. To squeeze maximum performance from this diverse fleet, software must translate high-level model operations into efficient, chip-specific instructions—known as optimized kernels. Traditionally, expert engineers hand-tune these kernels for each new chip generation and ML model architecture, a process that doesn't scale as the number of models and hardware types explodes. Enter KernelEvolve, an agentic kernel authoring system that automates this optimization, delivering significant throughput gains across Meta's ads ranking models and beyond.
The Kernel Optimization Challenge
Modern AI models rely on a variety of mathematical operations—general matrix multiplications (GEMMs), convolutions, attention mechanisms, and custom layers. While vendor libraries like NVIDIA's cuBLAS cover standard operators, production workloads require many custom operators that are unique to Meta's ranking models. Each operator must be implemented as a kernel tuned for specific hardware, considering memory access patterns, parallelism, and instruction-level optimizations. With models × hardware types × generations growing combinatorially, manual optimization becomes unsustainable. Engineers spend weeks profiling, optimizing, and cross-debugging kernels, often achieving suboptimal performance due to the sheer complexity of the search space.
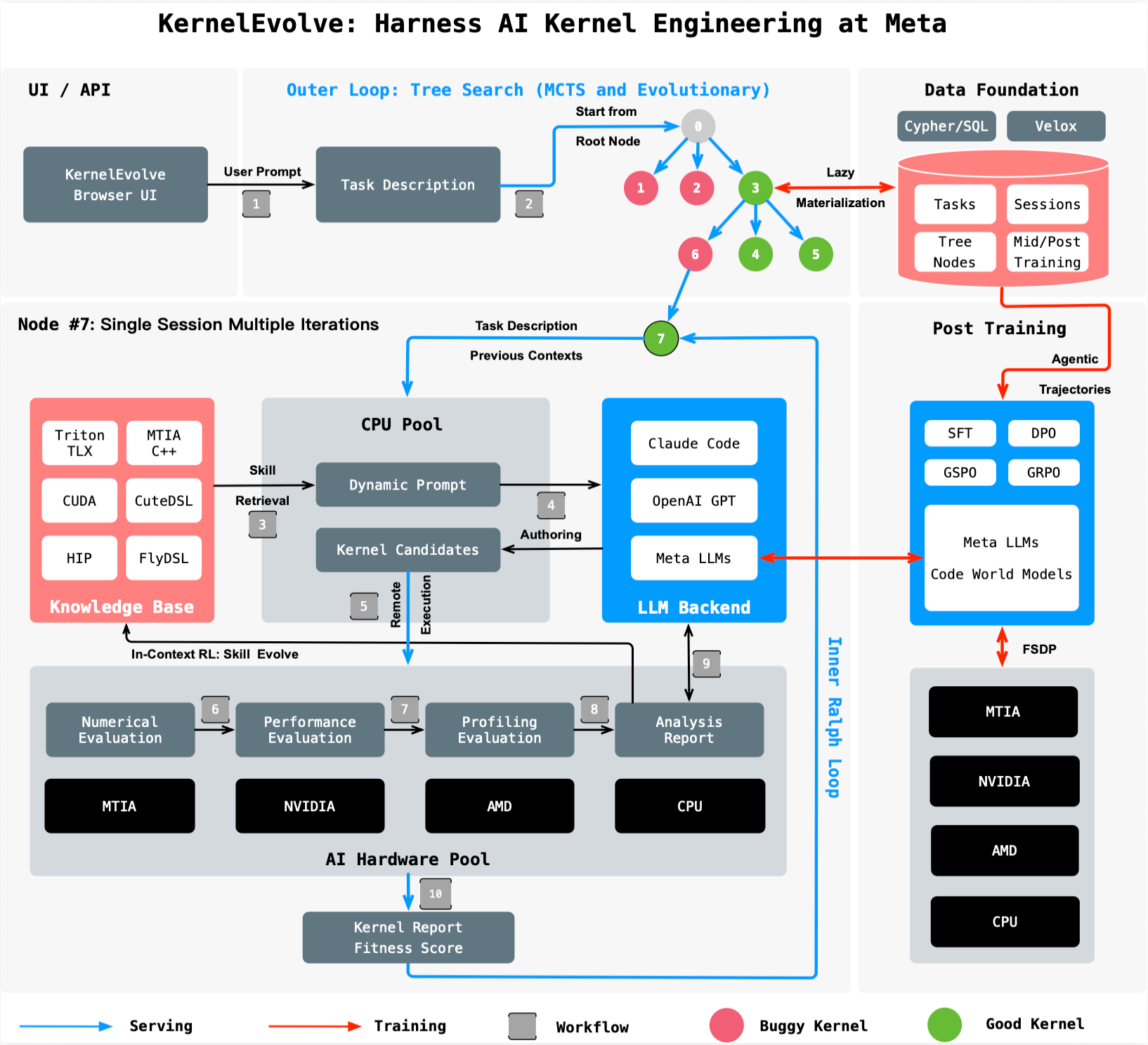
KernelEvolve: Agentic Kernel Optimization
KernelEvolve treats kernel optimization as a search problem. It is a purpose-built agent used by Meta's Ranking Engineer Agent to autonomously author and optimize kernels. The system works as follows:
- Candidate Generation: A large language model (LLM) proposes candidate kernel implementations in high-level domain-specific languages (DSLs) like Triton, Cute DSL, and FlyDSL, or in low-level languages such as CUDA, HIP, and MTIA C++.
- Evaluation Harness: A job harness runs each candidate on the target hardware, collecting performance metrics and diagnostics.
- Feedback Loop: The harness feeds diagnostics back to the LLM, which refines its proposals. This iterative process explores hundreds of alternatives, converging on high‑performing kernels that often exceed human‑expert results.
This approach transforms weeks of manual engineering into hours of automated search, freeing experts for higher‑level architecture work. Crucially, KernelEvolve is not limited to ads ranking—it is broadly applicable to any AI model requiring optimized kernels on Meta's heterogeneous infrastructure.
Performance Gains Achieved
KernelEvolve has delivered substantial improvements in both inference and training throughput:
- Over 60% inference throughput improvement for the Andromeda Ads model on NVIDIA GPUs. This means faster ad ranking decisions without additional hardware investment.
- Over 25% training throughput improvement for an ads model on Meta's custom MTIA silicon chips. Better training efficiency reduces the time and energy required to develop and update models.
These results demonstrate the system's ability to outperform hand‑tuned kernels, even on novel proprietary hardware like MTIA. The search‑based methodology adapts to each hardware–model combination, unlocking performance that manual tuning misses.
Broader Applicability and Impact
KernelEvolve's flexible design supports kernels for public and proprietary accelerators, including NVIDIA GPUs, AMD GPUs, MTIA chips, and CPUs. It generates code in multiple DSLs and low‑level languages, making it a cross‑platform optimization tool. Beyond ads ranking, the system is expected to optimize kernels for Meta's growing portfolio of AI workloads—from recommendation systems to generative AI. The ability to automatically tailor kernels to new chip generations as they emerge will be critical to sustaining Meta's AI innovation pace.
For more technical details, see the paper “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta” (ISCA 2026).
Conclusion
By reframing kernel optimization as an agentic search problem, KernelEvolve addresses a critical bottleneck in AI infrastructure scaling. It compresses expert engineering timelines, delivers double‑digit throughput gains, and works across a diverse hardware landscape. As AI models grow in complexity and hardware diversity increases, automated kernel authoring systems like KernelEvolve will become essential infrastructure components. Meta's results show that intelligent automation—not manual effort—is the key to unlocking the full potential of heterogeneous AI accelerators.
Related Articles
- 9 Key Highlights of the Fedora Linux 44 Release
- AMD Releases HDMI 2.1 FRL Patches for AMDGPU Linux Driver: What It Means for Users
- 10 Crucial Updates on Linux's sched_ext: Bug Fixes Driven by AI-Powered Code Reviews
- Upgrading Fedora Silverblue to Version 44: Your Step-by-Step Q&A Guide
- How to Diagnose and Resolve a CUBIC Congestion Window Bug in QUIC Implementations
- Ubuntu's Flavor Selection Gets Leaner: Why Quality Beats Quantity
- How to Protect Your Linux System from the Compromised Cemu Wii U Emulator Builds
- Policy Groups: A New Approach to Memory Management Beyond Control Groups