Kubernetes v1.36 Now Ships Stable PSI Metrics to Detect Resource Saturation Before Outages
Kubernetes v1.36 Graduates PSI Metrics to General Availability
Pressure Stall Information (PSI) metrics have officially graduated to General Availability in Kubernetes v1.36, providing operators with a stable, reliable interface to detect resource contention at the node, pod, and container levels before it escalates into an outage.
Unlike traditional utilization metrics that can mask latency issues, PSI measures the percentage of time tasks are stalled due to contention on CPU, memory, or I/O resources. This gives teams high-fidelity signals to pinpoint saturation early.
Beyond Utilization: Why PSI Matters
“Monitoring CPU or memory usage alone is misleading. A node may report only 80% CPU utilization yet tasks are experiencing severe scheduling delays,” said Dr. Aisha Patel, SIG Node technical lead. “PSI fills that gap by exposing cumulative stalled time and moving averages over 10s, 60s, and 300s windows.”
These windows help operators distinguish transient spikes from sustained resource pressure, enabling faster triage of performance degradation.
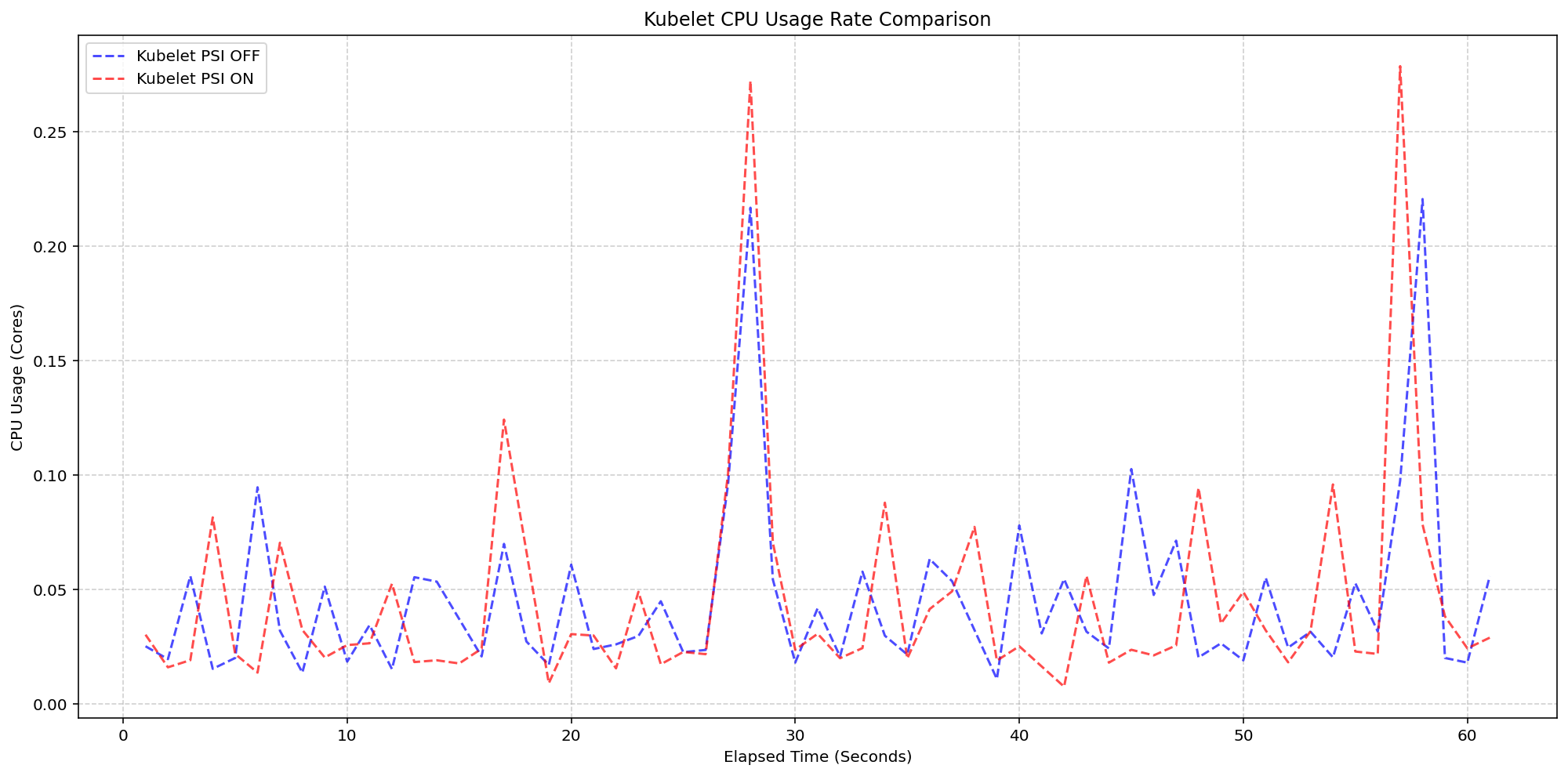
Performance Validation at Scale
SIG Node conducted rigorous performance testing on high-density workloads with over 80 pods across various machine types. Two scenarios isolated the overhead from the kubelet and the kernel respectively.
In the first scenario, on 4-core machines where the kernel already tracked PSI (psi=1), toggling the KubeletPSI feature gate showed that the kubelet's collection logic blends seamlessly into standard housekeeping cycles. CPU usage remained within normal bounds—0.1 cores or 2.5% of total node capacity.
The second scenario confirmed that once the OS is tracking PSI, the act of Kubernetes reading those cgroup metrics adds negligible overhead. System CPU usage for PSI-enabled clusters followed the same pattern as disabled clusters, with only a slight baseline increase.
Background
PSI was first introduced in the Linux kernel in 2018. It captures cumulative absolute time tasks spend in a stalled state, packaged as easy-to-interpret percentages. Prior to v1.36, PSI metrics were available as a beta feature, but operators relied on external tools or custom patches.
The graduation to GA means the feature is now production-ready, with strong guarantees around backward compatibility and performance. The community has long asked for first-class stall metrics, and this release delivers them without the need for additional agents.
What This Means
With stable PSI metrics, platform teams can now set proactive alerts on resource contention rather than relying on utilization thresholds that react too late. The ability to monitor at container granularity also helps in right-sizing requests and limits.
“This change fundamentally shifts how we approach capacity management,” added Dr. Patel. “Operators can now catch the precursors of an outage minutes or even hours earlier.”
The feature is enabled by default in v1.36. For existing clusters, upgrading ensures seamless access to PSI metrics via the kubelet and metrics APIs. SIG Node recommends testing on high-density workloads to validate the negligible overhead.
Related Articles
- Ubuntu's Twitter Hijacked in Multi-Stage Crypto Scam Following Sustained DDoS Attack
- 7 Key Insights into the Extended Ubuntu Infrastructure Outage
- 10 Critical Insights Into the Copy.Fail Linux Kernel Vulnerability
- Fedora 44 Atomic Desktops: Key Changes and What Users Need to Know
- Fedora Workstation 44 Launches with GNOME 50 and Enhanced Parental Controls
- Comprehensive Guide to This Week's Critical Security Patches Across Major Linux Distributions
- Strawberry Music Player Reaches New Milestone: A Full-Featured Linux Music Management Solution
- Exploring the Latest Developments in Open Source: April 30, 2026 LWN Edition